Chapter 3: Classification
19 min readThis chapter is all about systems that predict a category or a class – Is this email spam or not? Is this image a cat or a dog? Is this handwritten digit a ‘5’ or a ‘3’?
And speaking of handwritten digits, we’re going to be working with a very famous dataset: MNIST.
- It’s a set of 70,000 small images of digits (0-9) handwritten by high school students and US Census Bureau employees.
- Each image is labeled with the digit it represents.
- The book calls it the “hello world” of Machine Learning because it’s a go-to dataset for testing new classification algorithms. Everyone who learns ML eventually plays with MNIST. It’s like a rite of passage!
Scikit-Learn makes it super easy to fetch popular datasets like MNIST. The code shows:
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
This mnist object is a dictionary-like structure (a Scikit-Learn “Bunch” object, actually). The mnist.keys() output shows it contains:
'data': The features (the pixel values of the images).'target': The labels (the digit each image represents).'feature_names': Names of the features.'DESCR': A description of the dataset.- And a few others. This structure is common for datasets loaded with Scikit-Learn.
(Page 86: Exploring the MNIST Data)
Let’s look at the actual data arrays:
X, y = mnist["data"], mnist["target"]
X.shape gives (70000, 784)
y.shape gives (70000,)
- What does this mean?
- We have 70,000 images (
Xhas 70,000 rows). - Each image has 784 features (
Xhas 784 columns). Why 784? Because each image is 28x28 pixels, and 28 * 28 = 784. Each feature represents the intensity of one pixel, typically from 0 (white) to 255 (black). ycontains the 70,000 labels, one for each image.
- We have 70,000 images (
Let’s visualize one digit:
- Grab an instance’s feature vector:
some_digit = X[0](this is a flat array of 784 pixel values). - Reshape it to a 28x28 array:
some_digit_image = some_digit.reshape(28, 28). - Display it using Matplotlib’s
imshow():plt.imshow(some_digit_image, cmap="binary")(cmap=“binary” gives a black and white image).plt.axis("off")(to remove the axis ticks). The image on page 86 clearly looks like a ‘5’.
Let’s check its label:
y[0] gives '5'.
Notice the label is a string. Most ML algorithms expect numbers, so we convert y to integers:
y = y.astype(np.uint8) (np.uint8 is an unsigned 8-bit integer, good for values 0-255, perfect for digits 0-9).
(Page 87: MNIST Dataset Structure & Test Set)
Figure 3-1 shows a sample of the digits – you can see the variety and sometimes the messiness of handwriting!
Crucially, just like in Chapter 2, we need a test set!
The MNIST dataset as loaded by fetch_openml is often already split:
- First 60,000 images for training.
- Last 10,000 images for testing.
So, we can do:
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
The training set (X_train, y_train) is also typically pre-shuffled. This is good because:
- It ensures cross-validation folds will be similar (e.g., you don’t want one fold missing all images of the digit ‘7’).
- Some algorithms are sensitive to the order of training instances and perform poorly if they see many similar instances in a row. Shuffling prevents this. (The book notes shuffling isn’t always good, e.g., for time series data where order matters).
(Page 88: Training a Binary Classifier)
Let’s start simple. Instead of classifying all 10 digits, let’s try to identify just one digit – say, the number 5. This will be a binary classifier: it distinguishes between two classes, “5” and “not-5”.
Create target vectors for this binary task:
y_train_5 = (y_train == 5)# This will be True for all 5s, False for others.y_test_5 = (y_test == 5)Pick a classifier and train it: A good starting point is Scikit-Learn’s
SGDClassifier(Stochastic Gradient Descent classifier).- Why SGD? It’s efficient and can handle very large datasets because it processes training instances one at a time (making it suitable for online learning, too).
from sklearn.linear_model import SGDClassifiersgd_clf = SGDClassifier(random_state=42) - Why
random_state=42? SGD relies on randomness during training (hence “stochastic”). Settingrandom_stateensures reproducible results. If you run the code again, you get the same model.sgd_clf.fit(X_train, y_train_5)
- Why SGD? It’s efficient and can handle very large datasets because it processes training instances one at a time (making it suitable for online learning, too).
Make a prediction: Let’s use that
some_digit(which was a ‘5’) we looked at earlier:sgd_clf.predict([some_digit])returnsarray([True]). The classifier correctly guessed it’s a 5!
But one correct guess doesn’t mean much. We need to evaluate its overall performance.
(Page 88-93: Performance Measures for Classifiers)
Evaluating classifiers is often “significantly trickier than evaluating a regressor.” Get ready for new concepts!
Measuring Accuracy Using Cross-Validation (Page 89): Just like in Chapter 2, cross-validation is a good way to evaluate.
Implementing Cross-Validation Manually: The book shows how you could implement cross-validation yourself using
StratifiedKFold. This gives more control but is more work.StratifiedKFoldensures each fold has a representative ratio of each class (important for skewed datasets, where one class is much more frequent).- The loop creates a clone of the classifier, trains on training folds, predicts on the test fold, and calculates accuracy for that fold.
Using
cross_val_score(): Much easier!from sklearn.model_selection import cross_val_scorecross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")This performs K-fold cross-validation (here, 3 folds) and returns the accuracy for each fold. The output is something likearray([0.96355, 0.93795, 0.95615]). Wow! Over 93% accuracy on all folds! Seems amazing, right?The Pitfall of Accuracy with Skewed Datasets: Before getting too excited, let’s consider a “dumb” classifier:
class Never5Classifier(BaseEstimator):def fit(self, X, y=None): return selfdef predict(self, X): return np.zeros((len(X), 1), dtype=bool) # Always predicts False (not-5)If we runcross_val_scoreon thisNever5Classifier(page 90), we get over 90% accuracy!- Why? Only about 10% of the MNIST digits are 5s. So, if you always guess “not a 5,” you’ll be right about 90% of the time.
- Key takeaway: Accuracy is generally not the preferred performance measure for classifiers, especially with skewed datasets (where some classes are much more frequent than others).
Confusion Matrix (Page 90-91): A much better way to evaluate! It counts how many times instances of class A are classified as class B.
- Get “clean” predictions: Use
cross_val_predict():from sklearn.model_selection import cross_val_predicty_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)- This performs K-fold CV but returns the predictions made on each test fold (so each prediction is “clean” – made by a model that hadn’t seen that instance during its training).
- Compute the confusion matrix:
from sklearn.metrics import confusion_matrixconfusion_matrix(y_train_5, y_train_pred)The output (page 91) is a 2x2 matrix for our binary “5” vs “not-5” classifier:Predicted: Not-5 Predicted: 5 Actual: Not-5 [[ TN, FP ]] Actual: 5 [[ FN, TP ]]TN(True Negatives): Correctly classified as not-5 (e.g., 53,057).FP(False Positives): Wrongly classified as 5 (they were not-5) (e.g., 1,522). Also called a Type I error.FN(False Negatives): Wrongly classified as not-5 (they were 5s) (e.g., 1,325). Also called a Type II error.TP(True Positives): Correctly classified as 5 (e.g., 4,096). A perfect classifier would have only TPs and TNs (non-zero values only on the main diagonal). Figure 3-2 (page 92) provides a nice illustration of this.
- Get “clean” predictions: Use
Precision and Recall (Page 91-92): The confusion matrix is great, but sometimes we want more concise metrics.
- Precision (Equation 3-1): Accuracy of the positive predictions.
precision = TP / (TP + FP)- What it’s ultimately trying to achieve: Of all the instances the classifier claimed were positive (e.g., said were ‘5’s), what proportion were actually positive?
- A trivial way to get 100% precision: make only one positive prediction and ensure it’s correct. Not very useful!
- Recall (Equation 3-2): Sensitivity or True Positive Rate (TPR). Ratio of positive instances that are correctly detected.
recall = TP / (TP + FN)- What it’s ultimately trying to achieve: Of all the instances that were actually positive (e.g., all actual ‘5’s), what proportion did the classifier correctly identify?
Scikit-Learn provides functions:
from sklearn.metrics import precision_score, recall_scoreprecision_score(y_train_5, y_train_pred)gives ~72.9%.recall_score(y_train_5, y_train_pred)gives ~75.6%. So, when oursgd_clfclaims an image is a ‘5’, it’s correct only 72.9% of the time. And it only detects 75.6% of all actual ‘5’s. Not as shiny as the 90%+ accuracy suggested!- Precision (Equation 3-1): Accuracy of the positive predictions.
F₁ Score (Page 92): It’s often convenient to combine precision and recall into a single metric, especially for comparing classifiers. The F₁ score is the harmonic mean of precision and recall (Equation 3-3).
F₁ = 2 * (precision * recall) / (precision + recall)- What it’s ultimately trying to achieve: The F₁ score gives more weight to low values. So, a classifier only gets a high F₁ score if both precision and recall are high.
from sklearn.metrics import f1_scoref1_score(y_train_5, y_train_pred)gives ~74.2%.
The F₁ score isn’t always what you want. Sometimes you care more about precision (e.g., kid-safe video filter – high precision, even if recall is low). Sometimes you care more about recall (e.g., shoplifter detection – high recall, even if precision is low and there are false alarms).
Precision/Recall Trade-off (Page 93-96): Unfortunately, you usually can’t have it both ways: increasing precision tends to reduce recall, and vice-versa. This is the precision/recall trade-off.
How it works: Classifiers like
SGDClassifiercompute a decision score for each instance. If the score > threshold, it’s positive; else, negative. (Figure 3-3 illustrates this).- Raising the threshold: Fewer instances classified as positive. This usually increases precision (fewer false positives among the ones called positive) but decreases recall (more true positives get missed and become false negatives).
- Lowering the threshold: More instances classified as positive. This usually increases recall (fewer true positives missed) but decreases precision (more false positives creep in).
Scikit-Learn lets you access these decision scores:
y_scores = sgd_clf.decision_function([some_digit])SGDClassifieruses a threshold of 0 by default. If we setthreshold = 8000,(y_scores > threshold)might becomeFalse, meaning a ‘5’ is now missed (recall drops).Choosing a threshold:
- Get decision scores for all training instances:
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") - Compute precision and recall for all possible thresholds:
from sklearn.metrics import precision_recall_curveprecisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) - Plot precision and recall vs. threshold (Figure 3-4, page 95).
- Plot precision vs. recall (Figure 3-5, page 96).
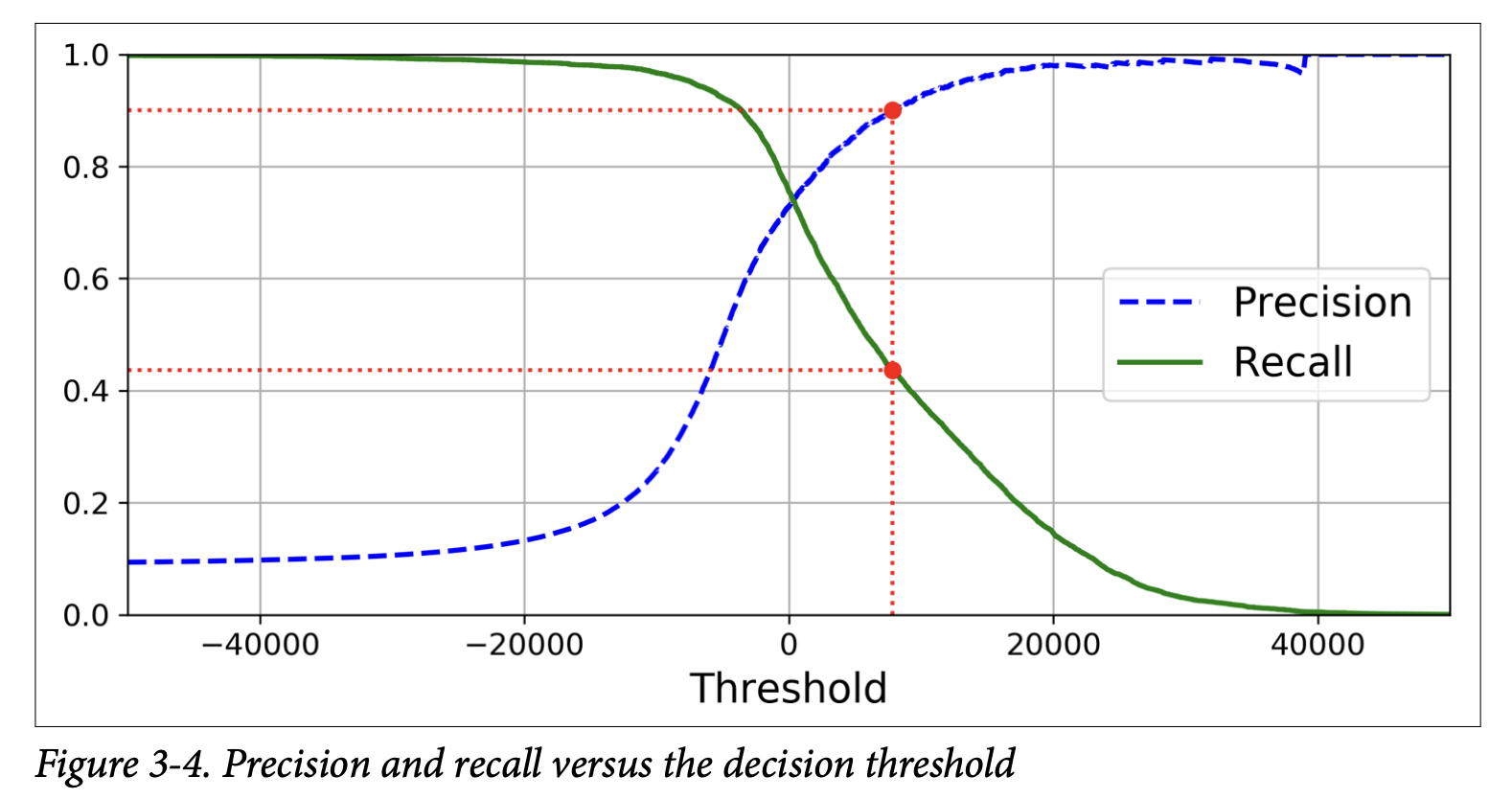
- Get decision scores for all training instances:
From these plots, you can choose a threshold that gives a good balance for your project. E.g., if you want 90% precision, find the threshold for that (around 8000 in the example, page 96). At this threshold, recall might be lower (e.g., 43.7%).
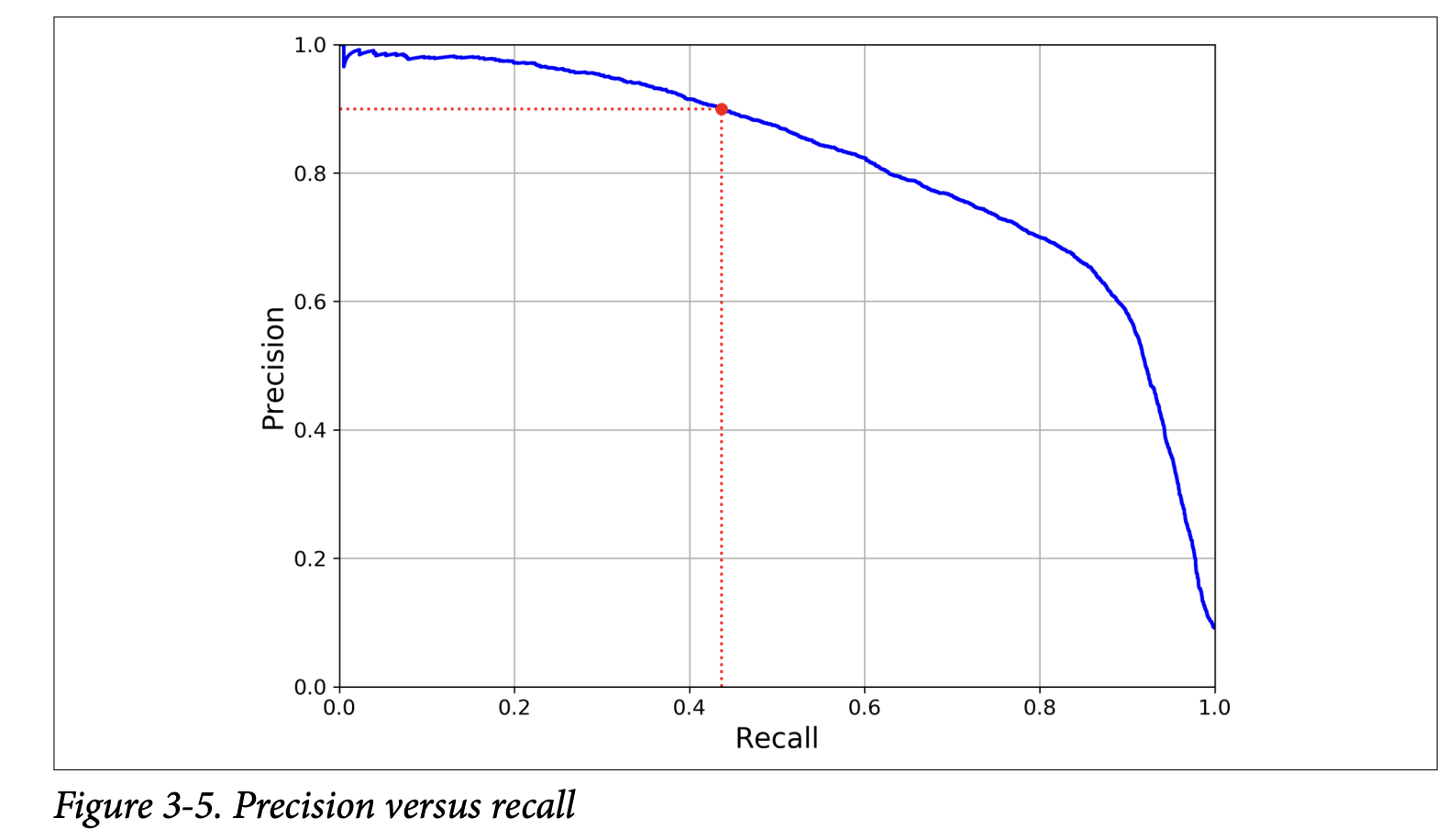
As the book wisely notes: “If someone says, ‘Let’s reach 99% precision,’ you should ask, ‘At what recall?’”
The ROC Curve (Page 97-99): Another common tool for binary classifiers: Receiver Operating Characteristic (ROC) curve.
- Plots True Positive Rate (TPR, which is just recall) against False Positive Rate (FPR).
FPR = FP / (FP + TN): Ratio of negative instances incorrectly classified as positive.- FPR is also
1 - True Negative Rate (TNR). TNR is called specificity. - So, ROC plots
sensitivity(recall) vs.1 - specificity.
- Plotting it:
- Compute TPR and FPR for various thresholds:
from sklearn.metrics import roc_curvefpr, tpr, thresholds = roc_curve(y_train_5, y_scores)(using the samey_scoresfromdecision_function). - Plot FPR vs. TPR using Matplotlib (Figure 3-6, page 98).
- Compute TPR and FPR for various thresholds:
- Interpretation:
- Dotted diagonal line: Purely random classifier.
- Good classifier: Stays as far away from the diagonal as possible (toward the top-left corner – high TPR, low FPR).
- Trade-off: Higher TPR (recall) usually means more FPRs.
- Area Under the Curve (AUC) or ROC AUC: A single number to compare classifiers.
- Perfect classifier: ROC AUC = 1.
- Random classifier: ROC AUC = 0.5.
from sklearn.metrics import roc_auc_scoreroc_auc_score(y_train_5, y_scores)gives ~0.96 forSGDClassifier.
- ROC vs. Precision-Recall (PR) Curve (Page 98 sidebar):
- When to use which? Prefer PR curve when positive class is rare OR you care more about false positives than false negatives. Otherwise, ROC is fine.
- MNIST ‘5’s are ~10% of data (positive class is somewhat rare). The ROC curve might look good because there are many true negatives. The PR curve might reveal more room for improvement.
- Comparing with RandomForestClassifier (Page 98-99):
RandomForestClassifierdoesn’t havedecision_function(). It haspredict_proba().predict_proba()returns an array: one row per instance, one column per class, with the probability of that instance belonging to that class.- Get probabilities for the positive class:
y_probas_forest = cross_val_predict(forest_clf, ..., method="predict_proba") y_scores_forest = y_probas_forest[:, 1](probabilities for the positive class, i.e., ‘5’).- Plot ROC for RandomForest (Figure 3-7, page 99). It’s much closer to top-left.
roc_auc_score(y_train_5, y_scores_forest)is ~0.998. Much better!- RandomForest also has much better precision (~99.0%) and recall (~86.6%).
- Plots True Positive Rate (TPR, which is just recall) against False Positive Rate (FPR).
(Page 100-102: Multiclass Classification)
So far, binary (5 vs. not-5). Now, distinguishing all 10 digits (0-9). This is multiclass classification (or multinomial).
Some algorithms (SGD, RandomForest, Naive Bayes) can handle multiple classes natively.
Others (Logistic Regression, SVMs) are strictly binary.
Strategies for using binary classifiers for multiclass:
- One-versus-the-Rest (OvR) or One-versus-All (OvA):
- Train N binary classifiers (one for each class). E.g., a 0-detector, a 1-detector, …, a 9-detector.
- To classify a new image: get decision score from each of the 10 classifiers. Select the class whose classifier outputs the highest score.
- One-versus-One (OvO):
- Train a binary classifier for every pair of digits. 0-vs-1, 0-vs-2, …, 1-vs-2, …, 8-vs-9.
- For N classes, this is N * (N-1) / 2 classifiers. For MNIST (N=10), it’s 45 classifiers!
- To classify: run image through all 45 classifiers. See which class “wins” the most duels.
- Main advantage: Each classifier is trained only on the subset of data for the two classes it distinguishes. Good for algorithms that scale poorly with training set size (like SVMs). For most others, OvR is preferred.
- One-versus-the-Rest (OvR) or One-versus-All (OvA):
Scikit-Learn’s behavior (page 101):
- It detects if you use a binary classifier for a multiclass task and automatically runs OvR or OvO.
- Example with
SVC(Support Vector Classifier):from sklearn.svm import SVCsvm_clf = SVC()svm_clf.fit(X_train, y_train)(Note:y_train, noty_train_5)svm_clf.predict([some_digit])correctly predicts[5].- Under the hood, SVC used OvO. It trained 45 binary classifiers.
svm_clf.decision_function([some_digit])returns 10 scores (one per class). The highest score corresponds to class ‘5’.svm_clf.classes_shows the list of target classes.
- You can force OvO or OvR:
from sklearn.multiclass import OneVsOneClassifier, OneVsRestClassifierovr_clf = OneVsRestClassifier(SVC())
SGDClassifier for multiclass (page 102):
- SGD can do multiclass natively. Scikit-Learn doesn’t need OvR/OvO.
sgd_clf.fit(X_train, y_train)sgd_clf.decision_function([some_digit])returns 10 scores. Class ‘5’ has the highest score (2412.5), class ‘3’ has a small positive score (573.5), others negative.- Evaluate with
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")-> gets ~84-87%. - Scaling inputs (as in Ch 2) with
StandardScalerimproves accuracy to >89%!scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))cross_val_score(sgd_clf, X_train_scaled, ...)
(Page 103-105: Error Analysis)
Assume you have a promising model. Now, analyze its errors to improve it.
- Multiclass Confusion Matrix:
- Get predictions:
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3) conf_mx = confusion_matrix(y_train, y_train_pred)- It’s a 10x10 matrix. Plot it with
plt.matshow(conf_mx, cmap=plt.cm.gray)(image on page 103).- Most images on main diagonal (correctly classified).
- The ‘5’s look slightly darker. Either fewer 5s, or classifier performs worse on 5s. (Book says both are true).
- Get predictions:
- Focus on errors:
- Divide each value in confusion matrix by number of images in the actual class (row sums) to get error rates.
row_sums = conf_mx.sum(axis=1, keepdims=True)norm_conf_mx = conf_mx / row_sums - Fill diagonal with zeros to keep only errors. Plot
norm_conf_mx(image on page 104).- Rows = actual classes, Columns = predicted classes.
- Column for class ‘8’ is bright: many images get misclassified as 8s.
- Row for class ‘8’ is not too bad: actual 8s are generally classified correctly.
- 3s and 5s often get confused (in both directions).
- Divide each value in confusion matrix by number of images in the actual class (row sums) to get error rates.
- What to do?
- Improve classification of digits that look like 8s (but aren’t). Gather more such training data.
- Engineer new features (e.g., count closed loops: 8 has two, 6 has one, 5 has none).
- Preprocess images to make patterns stand out (Scikit-Image, Pillow, OpenCV).
- Analyzing individual errors (page 104-105):
- Plot examples of 3s classified as 5s, 5s classified as 3s, etc. (Figure on page 105).
- Some errors are understandable (even humans would struggle).
- Many seem like obvious errors. Why does
SGDClassifier(a linear model) make them? It assigns a weight per pixel per class and sums weighted intensities. 3s and 5s differ by only a few pixels. - Sensitivity to shifting/rotation. Preprocessing (centering, de-skewing) could help.
(Page 106-107: Multilabel Classification)
Sometimes, an instance can belong to multiple binary classes.
- Example: Face recognition – if Alice and Charlie are in a picture, output should be [Alice:yes, Bob:no, Charlie:yes] or
[1, 0, 1]. - Simpler example with MNIST:
- Label 1: Is the digit large (7, 8, or 9)?
y_train_large = (y_train >= 7) - Label 2: Is the digit odd?
y_train_odd = (y_train % 2 == 1) - Combine into
y_multilabel = np.c_[y_train_large, y_train_odd](each instance has two labels).
- Label 1: Is the digit large (7, 8, or 9)?
- Train a classifier (e.g.,
KNeighborsClassifier, which supports multilabel):knn_clf = KNeighborsClassifier()knn_clf.fit(X_train, y_multilabel) - Prediction for
some_digit(a ‘5’):knn_clf.predict([some_digit])givesarray([[False, True]]). Correct! (5 is not large, 5 is odd). - Evaluation: Measure F₁ score for each label, then average.
f1_score(y_multilabel, y_train_knn_pred, average="macro")(“macro” gives equal weight to each label). Can setaverage="weighted"to weight by support (number of instances per label).
(Page 107-108: Multioutput Classification)
Generalization of multilabel: each label can be multiclass (not just binary).
- Example: Image denoising.
- Input: Noisy digit image (each pixel is an input feature).
- Output: Clean digit image (each pixel is a label, and each label can have values 0-255).
- This is multilabel (one label per pixel) and each label is multiclass (0-255 intensity).
- Create noisy data:
X_train_mod = X_train + noise. Target is clean image:y_train_mod = X_train. - Train
KNeighborsClassifier:knn_clf.fit(X_train_mod, y_train_mod). - Predict on a noisy test image:
clean_digit = knn_clf.predict([X_test_mod[some_index]]). - The result (image on page 108) looks close to the target!
The line between classification and regression can be blurry here (predicting pixel intensity). Multioutput systems can even mix class labels and value labels.
(Page 108-109: Exercises) The chapter concludes with some excellent exercises:
- Build a >97% accuracy classifier for MNIST (hint:
KNeighborsClassifierwith grid search). - Data augmentation: shift images, add to training set, retrain.
- Tackle Titanic dataset (Kaggle).
- Build a spam classifier (challenging!).
Glossary
Q . why does ROC curve exist only for binary classifiier?
That’s a sharp question! You’re right to notice that the ROC curve, as we’ve discussed it so far (plotting True Positive Rate vs. False Positive Rate), is fundamentally designed for and most intuitively understood in the context of binary classification.
Let’s break down why:
Clear Definition of “Positive” and “Negative” Classes:
- In binary classification, you have a clear distinction: one class is designated as “positive” (e.g., “is a 5,” “is spam,” “has disease”) and the other as “negative” (e.g., “is not a 5,” “is not spam,” “does not have disease”).
- This allows for unambiguous definitions of:
- True Positives (TP): Correctly identifying a positive instance.
- False Positives (FP): Incorrectly identifying a negative instance as positive.
- True Negatives (TN): Correctly identifying a negative instance.
- False Negatives (FN): Incorrectly identifying a positive instance as negative.
- TPR (Recall) = TP / (TP + FN)
- FPR = FP / (FP + TN) These metrics are the axes of the ROC curve.
Single Decision Threshold:
- Binary classifiers often output a score or probability that an instance belongs to the positive class. A single threshold is then used on this score to make the binary decision.
- The ROC curve visualizes performance across all possible values of this single threshold.
Why it’s tricky for multiclass classification (more than 2 classes):
When you have, say, 3 classes (A, B, C), the concepts of TP, FP, TN, FN become less straightforward if you try to apply them in the same way.
- What is “positive”? If you’re trying to detect class A, then A is “positive,” and B and C combined are “negative.” You could make an ROC curve for this “A vs. Not-A” scenario.
- What about class B? You’d then need a separate “B vs. Not-B” (where Not-B is A and C) scenario and its own ROC curve.
- And another for “C vs. Not-C.”
So, for a multiclass problem with N classes, you can’t draw a single, simple ROC curve in the same 2D TPR vs. FPR space that directly represents the performance across all classes simultaneously.
How ROC is often adapted or used in multiclass settings:
Even though a single ROC curve isn’t a direct fit, the underlying principles can be extended, typically using a One-vs-Rest (OvR) or One-vs-One (OvO) approach:
One-vs-Rest (OvR) ROC Curves:
- You can create
Nseparate binary classification problems. For each classi, you treat classias the positive class and all other classes (N-1of them) as the negative class. - You can then compute an ROC curve and its AUC for each of these
Nbinary problems. - This gives you
NROC curves andNAUC scores. - You can then, for example, average these AUC scores (e.g., macro-average or weighted-average) to get an overall performance metric for the multiclass classifier. Some libraries might even plot all N curves on the same graph or an “averaged” ROC curve, but this average curve can be harder to interpret directly than a binary ROC.
- You can create
One-vs-One (OvO) ROC Curves:
- You could, in theory, create an ROC curve for each pair of classes (N*(N-1)/2 curves). This becomes unwieldy very quickly and isn’t commonly done for overall visualization.
The Key Idea:
The ROC curve’s power lies in visualizing the trade-off for a single decision boundary between two distinct outcomes as you vary the threshold. In multiclass, you inherently have multiple potential decision boundaries between multiple classes, or you’re reducing it to multiple binary problems.
Think of it intuitively:
- Binary: “How good am I at separating the ‘good guys’ from the ‘bad guys’ as I change my definition of ‘suspicious activity’ (the threshold)?”
- Multiclass: If you have apples, oranges, and bananas, how would you define a single TPR and FPR that captures the misclassification rates between all pairs (apples called oranges, oranges called bananas, apples called bananas, etc.) on a single 2D plot in the same way? It’s not directly possible with the original TPR/FPR definitions.
In summary:
The standard ROC curve (TPR vs. FPR) is a tool specifically tailored for visualizing the performance of a binary classifier by showing its ability to distinguish between a positive and a negative class across various decision thresholds. While the concept can be extended to multiclass scenarios by breaking the problem down into multiple binary subproblems (like OvR), you won’t typically see a single, direct “multiclass ROC curve” in the same simple 2D form. Instead, you’d look at metrics derived from these multiple binary evaluations or other multiclass-specific evaluation tools (like a full confusion matrix for all classes).