One-Minute Video Generation with Test-Time Training
6 min readTLDR;
They tackled long video generation by replacing expensive global attention with efficient local attention, and bridging the gaps between local segments using novel TTT layers. These TTT layers act like RNNs but have a much smarter, adaptive hidden state (a neural network that learns on-the-fly during generation). This allows them to capture long-range dependencies and complex dynamics better than traditional RNNs, leading to more coherent minute-long videos, albeit with some remaining artifacts and efficiency challenges.
What’s the Problem they are trying to solve?
they want to create long videos, like a full minute long, that tell a coherent story with multiple scenes and characters doing things (like Tom chasing Jerry). Think of generating a mini-cartoon episode from a text description.
The main hurdle? Memory and Computation.
1. Transformers (The Standard Powerhouse): These models are amazing for many things, but they use something called “self-attention.” Imagine every frame in the video needing to look back and compare itself to every other frame that came before it. For a few seconds, this is fine. But for a minute-long video (which can be thousands of frames or tokens!), the computation becomes astronomically expensive – it scales quadratically (if you double the length, the cost goes up by four times!). It’s like trying to have a conversation where, before speaking, you have to re-read the entire transcript of everything said so far.
2. RNNs / State-Space Models (Like Mamba, DeltaNet - The Efficient Alternatives) : These are designed to be more efficient for long sequences. Their cost scales linearly (double the length, double the cost). Think of them like reading a book: you maintain a “summary” or “hidden state” in your head that captures the story so far, and you update it as you read each new word. Much faster.
- 2.1. The Catch: The “summary” these models keep (their hidden state) is usually quite simple, often just a matrix of numbers. While efficient, we found this simple summary isn’t expressive enough to capture the complex details needed for a dynamic, multi-scene story like Tom and Jerry. It struggles to remember specific details from long ago or juggle multiple interacting elements coherently. It’s like trying to summarize a complex movie plot in just one short sentence – you lose too much information.
Core Idea: Test-Time Training (TTT) Layers
So, we need the efficiency of RNNs but the expressiveness that approaches Transformers. How? We introduced Test-Time Training (TTT) Layers. Here’s the intuition:
- RNNs Revisited: Think of any RNN layer. It takes an input (xt) and its current “memory” or hidden state (Wt-1), updates that memory (Wt), and produces an output (zt).
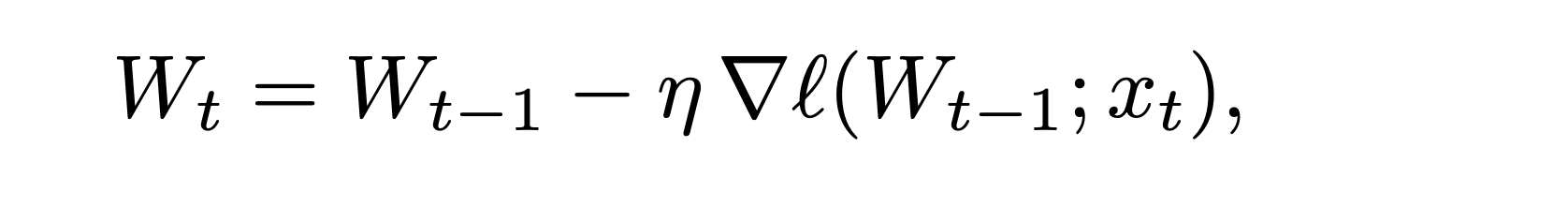
- Making the Memory Smarter: What if, instead of the hidden state (Wt) being just a passive matrix of numbers, it was itself a small neural network (f)? A mini-brain, if you will.
- Learning On-The-Fly: Now, here’s the key TTT part: As each new piece of the video sequence (xt) comes in during generation (at “test time”), we actually perform a tiny bit of training on this mini-brain hidden state. We update the weights (W) of this internal network f based on the input xt it just saw (using a quick gradient descent step, Equation 1).
Why “Test-Time Training”? Because this training/updating of the hidden state (W) happens while the model is generating the video (test time), not just during the initial, large-scale training phase.
- 4.1 The Benefit : Because the hidden state is now an active, learning neural network (they used a simple 2-layer MLP, see Section 2.3), it can potentially store much richer, more complex information than a static matrix. It adapts and learns specifically for the sequence it’s currently processing. This gives it a better chance to remember long-range dependencies and handle complex scene changes. It’s like having a smarter, adaptive summary that actively learns as the story unfolds.
Putting TTT into a Video Model (Section 3):
- Base Model: They didn’t start from scratch. We took a powerful pre-trained video generation model (CogVideo-X 5B) which was good at generating short (3-second) clips. The Problem: CogVideo-X uses standard Transformer attention, which is too slow for one minute.
The Approach (Figure 3):
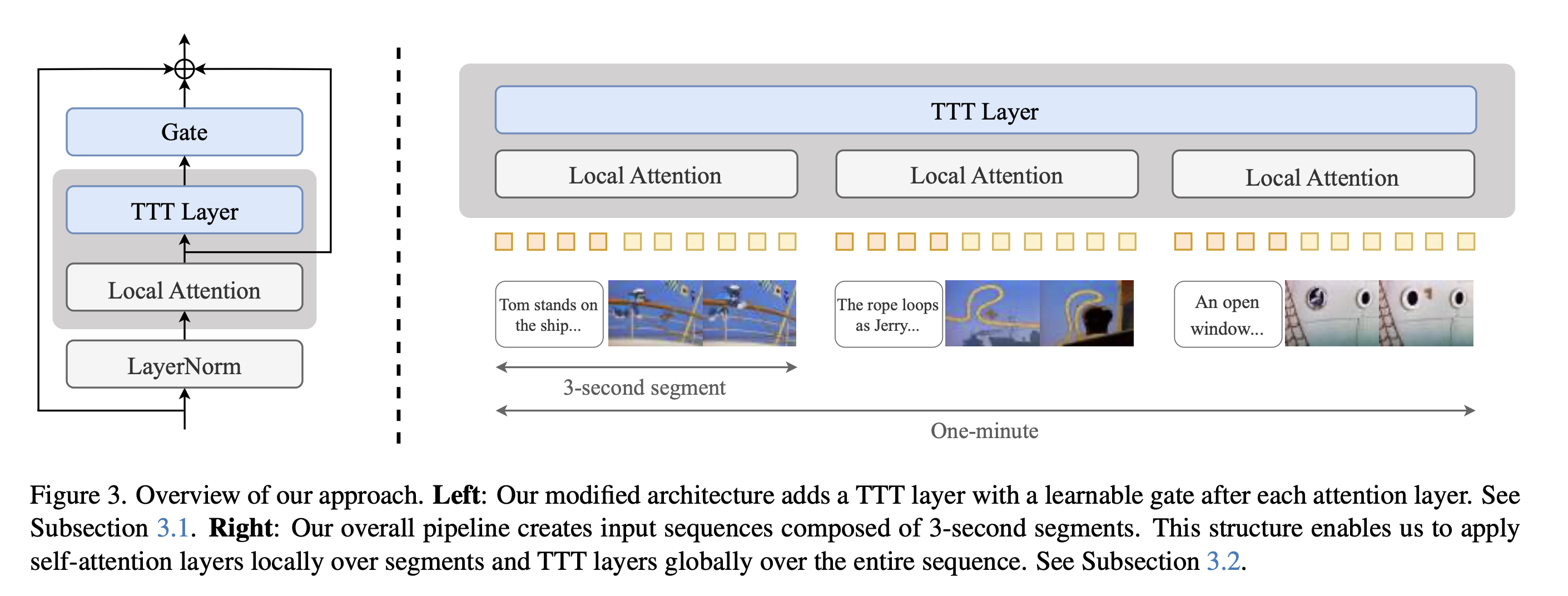
- Base Model: They didn’t start from scratch. We took a powerful pre-trained video generation model (CogVideo-X 5B) which was good at generating short (3-second) clips. The Problem: CogVideo-X uses standard Transformer attention, which is too slow for one minute.
The Approach (Figure 3):
- Local Attention: We keep the original Transformer self-attention layers but make them local. They only look at frames within their own 3-second segment. This keeps them fast.
- Global TTT: We insert our TTT layers. Since TTT layers are efficient (linear cost), we run them globally across the entire one-minute sequence. They act as the connective tissue, passing information between the 3-second segments that the local attention layers can’t see.
- Gating (Eq 6): When you add new layers (like TTT) to a pre-trained model, you don’t want them to mess things up initially. We use a “gate” (a learnable multiplier tanh(α)) that starts close to zero. This means, at first, the TTT layer’s output is mostly ignored. As the model fine-tunes, it can learn to “open the gate” (α increases) if the TTT layer proves helpful.
- Bi-direction (Eq 7): Video models often need to understand context from both past and future frames. Standard RNNs/TTT only look backward. So, we use a standard trick: run one TTT layer forward, and another identical TTT layer (TTT’) backward over the sequence, then combine their results. This gives each position information flowing from both directions.
- Segmentation: We process the video in 3-second chunks for the local attention, but the TTT layers see the whole concatenated sequence of chunks. Text prompts are also associated with these chunks (Format 3 storyboard). Training: We fine-tuned this modified architecture on our Tom and Jerry dataset, starting with short clips and gradually increasing the length (multi-stage context extension, Section 3.3).
Evaluation and Results (Section 4):
- They compared our TTT-MLP approach against strong baselines like Mamba 2, Gated DeltaNet (state-of-the-art RNNs), sliding-window attention, and a simpler TTT-Linear (where the hidden state f is just a linear layer, not an MLP).
- Key Finding: For long (one-minute) videos with complex stories, TTT-MLP performed significantly better than the baselines, especially in “Temporal Consistency” (making sense over time) and “Motion Naturalness” (realistic movement). It won by 34 Elo points on average in human evaluations (Table 1), which is a meaningful difference.
- Short Videos: Interestingly, for shorter 18-second videos (Table 3 in Appendix), Gated DeltaNet was slightly better, suggesting that the richer hidden state of TTT-MLP really shines when the context gets very long and complex.
- Limitations (Sec 4.4): It’s not perfect! Videos still have artifacts (weird physics, morphing objects - see Fig 7). It’s also computationally slower than Mamba or DeltaNet (Fig 6). The quality is also limited by the base CogVideo-X model.
Read the original paper: One-Minute Video Generation with Test-Time Training
The content presented here is a collection of my personal notes and explanations based on the paper. This is by no means an exhaustive explanation, and I strongly encourage you to read the actual paper for a comprehensive understanding.